The Iterative Incremental approach inherent in Agile applies to delivered functionality but also to the requirements elicitation part of the process.
I like to refine requirements over time. Start high level, just enough to remind us to have a conversation, then fill in the detail just as we need it. What starts as a simple name of an Epic Feature will turn into multiple User Stories each with several Scenarios. But you don’t need all of that at the start.
The iterative nature of requirements definition is suggestive of a spiral process – what my daughter would call a “snail”:
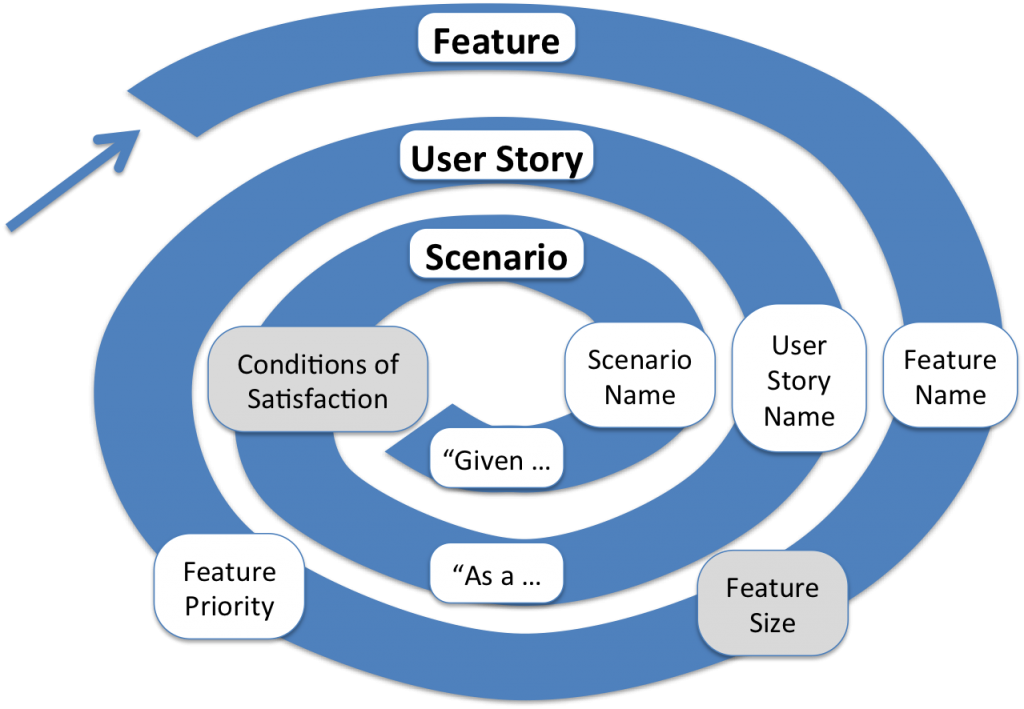
Agile Requirements Snail
Iteratively Refining Requirements
From my experience the details of the requirements emerge in roughly this order:
- Feature
- Name
- Size [Optional]
- Priority
- User Story
- Name
- “As <user role> I want to <action> so that <goal>”
- Conditions of Satisfaction [Optional]
- Scenario
- Name
- “Given <precondition> When <trigger> Then <result>”
The requirements are successively refined. They start as course features, which are split into small user stories, and end up as fine grained test scenarios. But even within each of those levels some aspects of the requirements come before others. The name of the feature comes before the size, priority and associated user stories. The name of the user story comes before the formal format (“As a …”) and conditions of satisfaction. The scenarios come last but even here the names of the scenarios usually come before the formal format (“Given …”).
Feature
Remembering that the cards on the board are just a reminder to have a conversation you can go a long way with just the name on the Feature card. The names should be short and snappy and instantly recognisable, for example “Search for Customer”.

Feature Card: Search For Customers
I use the term “Feature” here but in the XP and Scrum world “Epic” has general currency. I prefer the term “Feature” and the more refined version a Minimum Releasable Feature as labelling something an “Epic” just means it is big. In contrast a “Feature” and MRF are different to a user story and are managed in a different way.
It is the Features that populate my release plan. If I do need a development schedule – and some people don’t- then I will get an estimate on each Feature. For the last few years I’ve been using T-Shirt sizes (Small, Medium, Large) but Story Points are also good.
The last bit of data on a Feature is the priority of the item. I don’t record the priority on the card, which is why you don’t see one on the example. The priority is obvious from the where the Feature appears on the wall / product backlog.
Note: the number in the top left is just an unique ID. I have a habit of putting IDs on everything. So people can talk about Ticket #42 or the Feature “Search for Customer”.
User Story
I display the user story’s name prominently on the card on the board. As with Features, the names should be short and snappy and instantly recognisable. I find the name of the user story it much better as a reminder for the conversation than the formal format (“As a …”). The formal format is terribly verbose and as the only thing on the card obscures the core intent. The user story names are the labels in daily currency, e.g. somebody might ask “What is happening with Search by Name?” but is very unlikely to ask “What is happening with As a help desk operator I want to search for my customers by their first and last names so that customer response times remain short?”

User Story Card: Search by Name
People often put conditions of satisfaction on the back of user story card. I view the conditions of satisfaction as optional because they are quickly replaced by the scenarios. If conditions of satisfaction are listed they tend to be “happy path” scenarios.

User Story Card: Conditions of Satisfaction
Scenarios
Scenarios are the core of Specification by Example and Cucumber. In a “3 Amigos” style of meeting the product owner (and/or business analyst), developer and tester brain storm the names of the scenarios. You need all three perspectives to guarantee a full range of scenarios, both happy and unhappy paths. For example:
Feature: Search by Name As a help desk operator I want to search for my customers by their first and last names so that customer response times remain short Scenario: Combination of first and last name Scenario: First name only Scenario: Last name only Scenario: Hyphenated names Scenario: Blank name Scenario: Special characters only
The next step is to flesh out the scenarios with the formal format: “Given <precondition> When <trigger> Then <result>”. This might happen at the 3 Amigos meeting or after the meeting as homework by one of the team (typically the business analyst). The scenarios literally add specific examples to the spec.
Scenario: Hyphenated names
Given these customers:
| First Name | Last Name |
| Barry | White |
| Thomas | Burt |
| Bob | Griffiths |
| Amanda | Thomas-Griffiths |
When I search for Last Name of "Thomas-Giffiths"
Then search returns "1" customer with the name "Amanda Thomas-Griffiths"
What started as a fairly high level requirement, “Search for Customer”, has ended up as a set of very detailed and specific test scenarios, with the user stories as a kind of middle ground.
Steve this is an excellent post and gets the timing of story detail just right.
Hi Steven
Great article, thank you!
A couple of questions for you if you don’t mind:
You’ve mentioned that you are estimating at the Feature level to assist with the Development Schedule which feeds into the Release Plan…..furthermore at the (lower level) User Story level you are not estimating at all.
In your example Feature ‘Search for Customers’ you have a User Story ‘Search by Name’…….let’s pretend another separate User Story is created ‘Search by Member Number’ which also falls under this Feature.
Given that the Feature is at a higher level than the associated User Stories, how do you know what estimate to apply against the Feature given that you may not have yet identified (and estimated against) all of the lower level User Stories under this Feature? (After all, wouldn’t the sum of all lower level user stories ultimately be what the estimate against the Feature is?)
Also, I thought that the Dev Team selected the work that they are going to commit to for the upcoming iteration based on the (combined) sum of Story Points (assuming that Story Points are being used) not exceeding their velocity. How do they do this is if the estimate has only been applied at the Feature level and not at the User Story Level ?
Thanks
Adam
Adam
We estimate the Feature/Epic as a T-shirt size (XS, S, M, L, XL). This happens before articulating all of the user stories that make it up, but of course some of them will be obvious. There is some risk to that. The larger the item the bigger the risk as there is more opportunity for unexpected user stories to emerge. In our scheme a user story is by definition a XS.
Scrum advocates the team commit to deliver a set of functionality in a Sprint/Iteration. I no longer user Sprints/Iterations so this commitment is not necessary. In Kanban the team just pull in new requirements when they have capacity.
So I don’t estimate below the Feature/Epic level. Instead I count the Cucumber scenarios completed by the team. (If not using Cucumber then I count the user stories completed.) The original Feature/Epic estimate is a prediction of how many Scenarios (or User Stories) will pop out from the development team.
By leaving out the lower level estimates (I don’t distinguish between user stories and I don’t estimate tasks) I save time that the team can use on writing code. However, I also accept some risk that the estimate is out.
Hi Steven
Thanks for your explanation…..I have some further questions based on what you have said in addition to some other info I read on your site:
Firstly, my organization has just started on the Agile path and have chosen to go with Scrum and to work in Sprints/Iterations (at least for now). I also read your other article which contained info on Release Planning:
(https://itsadeliverything.com/agile-project-planning).
Admittedly this article was written back in 2008 and I presume at this point in time that you were using Sprints/Iterations (based on that article describing Release Planning which talks about the ‘Timebox Plan’ which I have taken to mean the Sprint/Iteration).
So I am hoping to draw on your experience even though you no longer work with Sprints/Iterations so that I can apply this to my situation.
Now, if I’ve interpreted the above mentioned article correctly along with your earlier response is it fair to say the following is accurate for what you did in the past and what you do now:
Where Sprints/Iterations were used:
Release Planning did not occur at the Feature/Epic level alone and instead first required breaking these down into User Stories (which were estimated).
Where Sprints/Iterations are NOT used:
Release Planning occurs at the Feature/Epic and the estimate used is based upon the number of Cucumber scenarios completed (or number of User Stories completed if not using Cucumber).
Have I got that right?
Thanks
Adam